Różne raporty i badania próbują uchwycić stopień rozwoju i przyjęcia sztucznej inteligencji w sektorze biznesowym.
Najbardziej kompleksowe raporty opublikowane do tej pory obejmują Stan polskiej sztucznej inteligencji w 2021 r. oraz Mapa polskiej sztucznej inteligencji 2019. Raporty te oferują obszerną listę polskich firm, nawet tych z małymi zespołami AI. Niestety, w ciągu ostatnich kilku lat wiele się zmieniło i szkoda, że raporty te nie zostały zaktualizowane.
Na uwagę zasługuje lista polskich startupów AI opracowanego przez dr Przemysława Chojeckiego w połowie 2023 r., obejmującego ponad 100 startupów, a także firm usługowych - software house'ów - specjalizujących się w AI. Podobna lista polskich startupówzostała stworzona przez Jana Szumadę.
Znacznie nowszy raport to w Raport EY: Jak polskie firmy wdrażają sztuczną inteligencję?. EY przebadał duży przekrój firm (ponad 500) o różnej wielkości i z różnych sektorów. Główny wniosek: 20% dużych i średnich przedsiębiorstw w Polsce wdrożyło systemy oparte na AI, a 80% firm, które zakończyły wdrożenie AI, twierdzi, że osiągnęło korzyści. Niestety, wyniki te budzą spore wątpliwości ze względu na brak pogłębienia tematu - co dokładnie rozumiemy przez “wdrożenie AI”?
Medyczne startupy (170 z Polski) są szczegółowo analizowane w raporcie Największe zakłócenia w opiece zdrowotnej. Niniejszy raport został przygotowany przez AI in Health Coalition, do której należą firmy (takie jak COGITA) oraz inne podmioty, których celem jest kształtowanie zastosowania sztucznej inteligencji w branży ochrony zdrowia w Polsce, z korzyścią zarówno dla pacjentów, jak i lekarzy.
Platforma zainicjowana przez ministerstwo, ai4msp.pl, prezentuje wiele wdrożeń projektów AI przez polskie firmy. W założeniu ma pełnić rolę marketplace'u, choć trudno ocenić jego obecne znaczenie rynkowe.
Podcasty i wywiady, takie jak Nieliniowy lub 99twarzyAI, stanowią dość dobry przegląd tego, co faktycznie dzieje się ze sztuczną inteligencją w polskich firmach.
Warto zauważyć, że w erze generatywnej sztucznej inteligencji firmy coraz częściej koncentrują się na szkoleniu własnych pracowników (działów IT lub innych) i testowaniu rozwiązań AI wewnętrznie, zamiast zlecać pracę wykwalifikowanym Data Scientistom, którzy do niedawna mieli monopol na tworzenie systemów uczenia maszynowego i sztucznej inteligencji.
W ramach stowarzyszenia polskich firm programistycznych SoDA działa grupa robocza ds. sztucznej inteligencji.Grupa badawcza SoDA AI-założona w ubiegłym roku, składająca się z około 100 członków z 30 polskich firm AI.
Na uwagę zasługują dwa raporty przedstawione przez tę grupę. Współpraca człowieka ze sztuczną inteligencją: Perspektywy dla polskiego sektora publicznego zawiera przykłady projektów AI zrealizowanych w różnych obszarach sektora publicznego i związanych z nimi wyzwań. Tymczasem raport Generatywna sztuczna inteligencja w biznesie (współtworzony przez więcej podmiotów niż tylko SoDA) skupia się stricte na sztucznej inteligencji generatywnej i prezentuje jej potencjał w różnych branżach. Raport ten koncentruje się bardziej na pokazaniu możliwości i narzędzi niż na przedstawieniu rzeczywistych wdrożonych projektów AI.
W ostatnich miesiącach Komora AI Powstała również izba handlowa, która obecnie zrzesza 44 firmy zajmujące się rozwiązaniami AI.
W ciągu ostatniego półtora roku odnotowano również ogromny wzrost zainteresowania sztuczną inteligencją ze strony osób nietechnicznych, programistów, którzy do tej pory zajmowali się innymi technologiami, a także osób rozwijających własne firmy.
Różne grupy stworzyły godne uwagi szkolenia, społeczności i platformy, takie jak Elephant AI, AI_Devs, Sztuczna inteligencja kampusu, lub Tworzenie produktów AI. Kursy te różnią się znacznie poziomem i wynikami, często prowadząc osoby do udziału w kilku różnych szkoleniach. Niektóre kursy mają tysiące uczestników.
Jeśli chodzi o wydarzenia branżowe, od dawna cykliczne, bardziej techniczne inicjatywy nadal się rozwijają, takie jak Data Science Summit, ML w PL, PyData, lub warsaw.ai. Pojawiają się jednak również bardziej lokalne inicjatywy dla entuzjastów AI, takie jak Śniadania AI, Mazowiecki AI Fest, lub GenAI Kraków.
W tej kategorii SpeakLeash Warto również wspomnieć o społeczności, która obejmuje ponad 1000 entuzjastów zjednoczonych wokół idei stworzenia dużego korpusu danych języka polskiego, który jest następnie wykorzystywany do szkolenia polskich LLM.
Świetna analiza tego, co dzieje się w polskiej nauce w zakresie AI, została przedstawiona w artykule Raport IDEAS NCBR “Zatrzymywanie najlepszych - trendy w kształceniu doktorantów w dziedzinie sztucznej inteligencji”. Wynika z niego, że w ciągu ostatnich 3,5 roku w Polsce obroniono zaledwie 200 doktoratów z zakresu sztucznej inteligencji. Jest to niewielka liczba, biorąc pod uwagę szybki rozwój tej dziedziny.
Warto zauważyć, że w dobie szybkich zmian napędzanych przez sztuczną inteligencję, autorytetami w tej dziedzinie są często osoby wykształcone w innych dziedzinach (filozofia, zarządzanie) lub celebryci. Osoby takie zyskują duże grono odbiorców swoim krzykliwym przekazem marketingowym, oferując swoje wystąpienia na konferencjach, konsultacjach czy szkoleniach.
Przykładem listy, która próbowała wybrać najbardziej wpływowe osoby w AI, jest artykuł “23 najbardziej wpływowych Polaków w AI” przygotowany przez MyCompany Polska.
W dziedzinie sztucznej inteligencji należy również wspomnieć o inicjatywach rządowych i międzynarodowych. Od 2016 r. rozwijana jest platforma Strategia AI było w toku, a kamieniem milowym było przyjęcie “Polityka rozwoju sztucznej inteligencji w Polsce od 2020 roku. Dokument ten przeszedł jednak w dużej mierze bez echa w polskim biznesie, co utrudnia ocenę jego roli w kształtowaniu rzeczywistości związanej ze sztuczną inteligencją.
Wydaje się, że wdrożenie unijnej ustawy o sztucznej inteligencji, której prekonsultacje, które niedawno się zakończyły, odegrają znacznie większą rolę.
Od 2018 roku Ministerstwo Cyfryzacji prowadzi program Grupa robocza ds. sztucznej inteligencji, ale mimo szerokiego przekroju specjalistów i kilku raportów, trudno zauważyć szerszy wpływ tej grupy na rzeczywistość związaną z AI w Polsce.
Z pewnością programy finansowania publicznego, takie jak Ścieżka Smart odgrywają znaczącą rolę w rozwoju firm, choć wydają się niewystarczające w porównaniu z funduszami przeznaczonymi na rozwój AI w innych krajach.
Tradycyjne metody kontroli jakości są często czasochłonne i podatne na błędy ludzkie, co prowadzi do nieefektywności i zwiększonych kosztów. W tym artykule przedstawiamy hipotetyczne studium przypadku ilustrujące, w jaki sposób zaawansowany system wykrywania obrazu może zrewolucjonizować kontrolę jakości w przemyśle spożywczym, na przykładzie dużej firmy zajmującej się przetwórstwem owoców i warzyw.
Firma specjalizuje się w produkcji dżemów, soków, warzyw w puszkach i mrożonek. Codziennie przetwarza tysiące ton surowców na swoich rozległych liniach produkcyjnych. Głównym wyzwaniem dla firmy jest utrzymanie wysokiej jakości produktów, minimalizacja odpadów i szybka identyfikacja wad produkcyjnych, takich jak zanieczyszczenia, uszkodzenia mechaniczne owoców i warzyw oraz niezgodność z normami jakości. Tradycyjne metody kontroli jakości okazały się niewystarczające, co skłoniło firmę do wdrożenia zautomatyzowanego systemu wykrywania obrazów opartego na sztucznej inteligencji.
Celem projektu było opracowanie i wdrożenie zaawansowanego systemu sztucznej inteligencji, który automatycznie kontrolowałby produkty spożywcze na linii produkcyjnej, identyfikując wady i uszkodzenia. System miał na celu zwiększenie wydajności kontroli jakości poprzez automatyzację procesu, zmniejszenie strat produkcyjnych dzięki szybkiemu wykrywaniu wad oraz poprawę ogólnej jakości produktów dostarczanych na rynek, prowadząc do większej satysfakcji klientów.
Trzy miesiące przed rozpoczęciem projektu firma zainstalowała kamery na kluczowych etapach linii produkcyjnej. Kamery zostały zainstalowane przy wlocie surowców, na liniach sortowniczych i przy maszynach pakujących. Te strategiczne lokalizacje pozwoliły na monitorowanie jakości surowców i produktów na różnych etapach produkcji. Kamery rejestrowały obrazy surowców, takich jak jabłka, pomidory, papryka, marchew i ziemniaki, które były następnie analizowane pod kątem wad i uszkodzeń.
W ciągu trzech miesięcy firma zebrała około 500 000 rekordów obrazów, przy czym codziennie przybywało około 5 000 nowych obrazów. Dane te były przechowywane na lokalnych serwerach i w chmurze, zapewniając łatwy dostęp do dużych zbiorów danych. Każdy rekord zawierał znacznik czasu, lokalizację na linii produkcyjnej, typ produktu i opis wady, jeśli została wykryta. Podczas gromadzenia danych niektóre metody i lokalizacje kamer zostały zmodyfikowane w celu poprawy jakości zebranych danych. Brakujące dane zostały uzupełnione przez dodatkowe sesje zdjęciowe i ulepszenia konfiguracji kamer.
Do implementacji systemu wykorzystano zaawansowane technologie i narzędzia sztucznej inteligencji, takie jak Pytorch i OpenCV. Konwolucyjne sieci neuronowe (CNN) zostały wybrane ze względu na ich skuteczność w zadaniach analizy obrazu, dzięki ich zdolności do automatycznego wykrywania cech i wzorców. Wykorzystano również uczenie transferowe, wykorzystując wstępnie wytrenowany model YOLO, który został dostosowany do specyficznych danych przemysłu spożywczego.
Dane obrazu zostały wstępnie przetworzone przy użyciu OpenCV, w tym korekcji kolorów, normalizacji oświetlenia i usuwania szumów. Rozszerzenie danych, takie jak obrót, skalowanie oraz zmiany jasności i kontrastu, zostało zastosowane w celu zwiększenia zbioru danych szkoleniowych i poprawy uogólnienia modelu. Modele CNN zostały wytrenowane na dużych zbiorach danych obrazów, obejmujących różne klasy surowców i różne rodzaje defektów. Proces uczenia został przyspieszony przy użyciu procesorów graficznych z technologią NVIDIA CUDA, umożliwiając wydajne przetwarzanie dużych zbiorów danych.
Model wykrywania obrazów został wdrożony na serwerach AWS z obsługą GPU, aby zapewnić szybkie przetwarzanie danych obrazu. Do skalowania i zapewnienia wydajności systemu wykorzystano serwery AWS EC2 z instancjami p3.2xlarge. Interfejs API RESTful został utworzony przy użyciu Flask, umożliwiając komunikację między systemem wykrywania obrazów a linią produkcyjną. API obsługiwało żądania HTTP POST do wysyłania obrazów i odbierania wyników analizy.
Interfejs API został zintegrowany z istniejącym systemem produkcyjnym firmy, umożliwiając automatyczne przesyłanie obrazu z kamer do systemu wykrywania obrazu. System produkcyjny wysyłał obrazy do API w czasie rzeczywistym, a wyniki analizy były zwracane do systemu produkcyjnego w celu podjęcia odpowiednich działań, takich jak usunięcie wadliwych produktów z linii.
Narzędzia do monitorowania i zarządzania, takie jak Amazon CloudWatch, zostały wdrożone w celu zapewnienia ciągłej dostępności i wydajności systemu.

System osiągnął dokładność 80% w wykrywaniu wad surowców, co przyniosło producentowi znaczące korzyści biznesowe. Wdrożenie zmniejszyło ilość odpadów produkcyjnych o 20%, co odpowiada 10 tonom mniej odpadów miesięcznie.
Wydajność kontroli jakości surowców wzrosła o 50%, prowadząc do szybszych i dokładniejszych inspekcji. Zakładając, że koszt pracy związanej z kontrolą jakości surowców wynosi 50 000 PLN miesięcznie, oszczędności wynikające ze zwiększonej wydajności wyniosły 25 000 PLN miesięcznie.
W projekt zaangażowanych było trzech analityków danych i kierownik projektu pracujący w niepełnym wymiarze godzin. Projekt trwał 4 miesiące i obejmował przygotowanie danych, szkolenie w zakresie modeli i wdrożenie systemu.
Serwery AWS zostały wykorzystane do szkolenia modeli i wdrożenia systemu wykrywania obrazów. Trening modelu na instancjach EC2 p3.2xlarge kosztował 10 600 PLN za 900 godzin pracy. Wdrożenie i operacje na instancjach EC2 t3.large kosztowały 900 PLN za 4 miesiące pracy. Przechowywanie danych na Amazon S3 kosztowało 700 PLN za 2 TB danych w ciągu 4 miesięcy, a wykorzystanie Amazon RDS do przechowywania bazy danych kosztowało 1 100 PLN.
Całkowity koszt projektu wyniósł 513 300 PLN.
System był monitorowany pod kątem dostępności i wydajności za pomocą Amazon CloudWatch, a modele wykrywania obrazów były regularnie aktualizowane co miesiąc, aby uwzględnić zmiany w surowcach i nowe typy wad. System alertów informował zespół o wszelkich nieprawidłowościach, takich jak spadki wydajności lub problemy z dostępnością danych.
Współpraca między zespołami miała kluczowe znaczenie dla powodzenia projektu. Regularnie odbywały się spotkania pomiędzy zespołami data science, IT, produkcji i zarządzania jakością w celu omówienia postępów projektu, wymiany pomysłów i identyfikacji potencjalnych problemów. Wszystkie etapy projektu zostały dokładnie udokumentowane, w tym specyfikacje techniczne, raporty z analizy danych, wyniki testów A/B i zalecenia dotyczące dalszych działań. Przeprowadzono szkolenie dla zespołu produkcyjnego w zakresie korzystania z systemu wykrywania obrazów i interpretacji wyników w celu maksymalnego wykorzystania potencjału narzędzia.
Projekt stanął przed kilkoma wyzwaniami, takimi jak zapewnienie skalowalności systemu w celu obsługi rosnących ilości danych i surowców oraz ciągłe poprawianie dokładności modelu wykrywania poprzez regularne aktualizacje i optymalizację algorytmów. Integracja z różnymi systemami produkcyjnymi i zapewnienie kompatybilności również stanowiły wyzwanie.
W przyszłości producent żywności planuje rozszerzyć zakres wykrywania, wprowadzając wykrywanie innych rodzajów wad, takich jak deformacje strukturalne lub zmiany koloru. Zwiększenie automatyzacji poprzez bardziej zaawansowane mechanizmy decyzyjne na linii produkcyjnej oraz wykorzystanie zaawansowanej analityki do przewidywania problemów jakościowych i optymalizacji procesów produkcyjnych to kolejne kroki w rozwoju systemu.
Wdrożenie zaawansowanego systemu detekcji obrazu przyniosło znaczące korzyści, takie jak zmniejszenie ilości odpadów produkcyjnych, zwiększenie wydajności kontroli jakości surowców i poprawa jakości produktów. Chociaż projekt napotkał pewne wyzwania, korzyści biznesowe z wdrożenia systemu były znaczące, a firma planuje dalszy rozwój i optymalizację systemu w przyszłości.
To hipotetyczne studium przypadku pokazuje, w jaki sposób sztuczna inteligencja może zrewolucjonizować branżę spożywczą, przynosząc wymierne korzyści zarówno producentom, jak i konsumentom.
Sklepy internetowe muszą stale dostosowywać swoją ofertę do potrzeb i preferencji klientów, aby zwiększyć współczynniki konwersji i wartość koszyka.
Poniżej omówimy krok po kroku hipotetyczny projekt wdrożenia zaawansowanego systemu rekomendacji w sklepie elektronicznym, który może znacznie poprawić wskaźniki sprzedaży i doświadczenia zakupowe klientów.
Sklep internetowy specjalizujący się w elektronice (laptopy, smartfony, telewizory i akcesoria) zauważył, że wielu klientów opuszczało witrynę bez dokonania zakupu. Pomimo szerokiej gamy produktów, użytkownicy mieli trudności ze znalezieniem produktów odpowiadających ich potrzebom. W rezultacie współczynniki konwersji i średnia wartość koszyka były niższe niż oczekiwano, co negatywnie wpłynęło na przychody i rentowność sklepu.
Celem projektu było opracowanie i wdrożenie zaawansowanego systemu rekomendacji:
W projekcie wykorzystano różne źródła danych kluczowe dla pomyślnego wdrożenia systemu rekomendacji:
Aby zapewnić jakość danych, podjęto działania mające na celu
Przygotowanie i przetwarzanie danych
Przed zbudowaniem systemu rekomendacji podjęto kilka działań w celu uzyskania cennych informacji biznesowych:
W implementacji systemu rekomendacji wykorzystano różne modele i technologie sztucznej inteligencji:
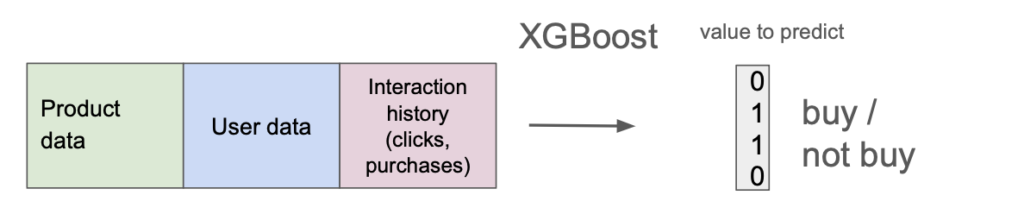
Po wdrożeniu systemu przeprowadzono testy A/B. System rekomendacji zwrócił wyniki dla 50% losowo wybranych użytkowników, podczas gdy pozostali otrzymali zwykłą kolejność produktów (według popularności). Pozwoliło to na precyzyjny pomiar jakości modelu.
Głównymi kosztami projektu były wynagrodzenia zespołu programistów.
Czas trwania projektu: 2 miesiące.
Ponieważ cały system został wdrożony w chmurze, wiązało się to z dodatkowymi kosztami:
Całkowity koszt projektu: 303 870 PLN.
W ten sposób inwestycja zwróciła się dwa tygodnie po wdrożeniu rozwiązania.
Po wdrożeniu modelu uczenia maszynowego kluczowe było monitorowanie jego wydajności i wprowadzanie niezbędnych korekt.
Monitorowanie zostało wdrożone przy użyciu Amazon CloudWatch. Ze względu na wprowadzanie nowych produktów i zmieniające się preferencje użytkowników, wdrożono automatyczne cotygodniowe przekwalifikowanie modelu. Dodatkowo wprowadzono system alertów w celu zgłaszania anomalii.
Dla każdego polecanego produktu użytkownicy mogli kliknąć kciuk w górę lub w dół, aby ocenić jakość rekomendacji. Zapewniło to dodatkowe źródło informacji przydatnych do przekwalifikowania modelu sztucznej inteligencji.
Hipotetyczne wdrożenie zaawansowanego systemu rekomendacji w sklepie z elektroniką było kluczowym krokiem w kierunku poprawy doświadczeń zakupowych klientów i zwiększenia efektywności sprzedaży.
Personalizując ofertę produktową w oparciu o preferencje użytkowników, osiągnięto zauważalną poprawę współczynników konwersji i średniej wartości koszyka.
Projekt wymagał integracji danych z różnych źródeł i zastosowania zaawansowanych technologii uczenia maszynowego, takich jak XGBoost, które umożliwiły efektywne przetwarzanie i analizę dużych ilości danych oraz generowanie dokładnych rekomendacji produktów w czasie rzeczywistym.
W ostatnich latach byliśmy świadkami kilku przełomowych momentów, takich jak stworzenie modelu AlphaZero w 2017 r., który osiągnął poziom arcymistrzowski w szachach i Go, oraz opracowanie architektury Transformer w tym samym roku, która stanowi podstawę wielu modeli przetwarzania języka. Jednak wydanie modelu GPT-3.5 jako chatbota, ChatGPT, 30 listopada 2022 r., zwróciło uwagę opinii publicznej na sztuczną inteligencję. Wykorzystanie sztucznej inteligencji stało się powszechne w życiu prywatnym i poszukiwaniu zastosowań biznesowych w celu zaoszczędzenia czasu, usprawnienia procesów i zwiększenia zysków.
Należy zauważyć, że wykorzystanie algorytmów opartych na sztucznej inteligencji (a dokładniej, na uczeniu maszynowym) w zastosowaniach biznesowych trwa już od co najmniej kilku lat. Typowe przykłady obejmują systemy rekomendujące reklamy lub inne treści użytkownikom Internetu, systemy predykcyjne w instytucjach finansowych oraz algorytmy wykrywania obrazów w przemyśle. Choć algorytmy te wciąż ewoluują, firmom daleko jeszcze do pełnego wykorzystania potencjału AI.
Dlatego w tym artykule nie tylko przedstawię, jak wykorzystać generatywną sztuczną inteligencję (taką jak ChatGPT czy Midjourney) w swojej firmie, ale także szerzej opiszę, jak podejść do identyfikacji obszarów, które można usprawnić za pomocą różnego rodzaju algorytmów AI.
Swoją przygodę ze sztuczną inteligencją warto rozpocząć od zapoznania się z dostępnymi narzędziami. Jest ich już całkiem sporo, a każde z nich służy bardzo różnym zastosowaniom. Oto kilka przykładów.
Adobe Firefly to zaawansowane narzędzie do generowania i edycji grafiki, idealne dla działów marketingu i projektowania. Z kolei Synthesia pozwala na tworzenie filmów z generowanymi głosami i postaciami, co jest świetnym rozwiązaniem do produkcji materiałów szkoleniowych i prezentacji.
ChatGPT i Gemini to wszechstronne narzędzia, które mogą pomóc w tworzeniu treści marketingowych, obsłudze klienta, odpowiadaniu na wiadomości e-mail lub generowaniu pomysłów. Grammarly z kolei pomaga poprawić gramatykę i styl pisania, co jest nieocenione przy tworzeniu wysokiej jakości treści marketingowych i raportów.
Turbologo i Logopony to narzędzia do generowania logo, które mogą przyspieszyć proces tworzenia identyfikacji wizualnej firmy. Canva oferuje szeroką gamę narzędzi do projektowania, w tym te wykorzystujące generatywne modele AI. Wysokiej jakości grafiki można tworzyć za pomocą Midjourney lub Leonardo.ai. Jeśli potrzebujesz podkładu muzycznego, sprawdź Suno.
Narzędzia takie jak Slides AI, Presentations AI, Pitch i Beautiful.AI umożliwiają tworzenie atrakcyjnych prezentacji z automatycznym formatowaniem, co może znacznie zaoszczędzić czas i poprawić jakość wizualną prezentowanych materiałów.
Nie zapomnij skorzystać z narzędzi do transkrypcji spotkań, takich jak OtterAI, i systemów podsumowujących tekst, takich jak SummarizeBot.
Dla zespołów badawczych Scite.AI oferuje zaawansowane możliwości wyszukiwania informacji naukowych i znacznie przyspiesza proces badawczy.
Warto eksperymentować z różnymi narzędziami, aby znaleźć te, które najlepiej spełniają potrzeby Twojej firmy. Z pewnością zwiększą one efektywność Twoich pracowników. Jednak korzystanie z tych narzędzi to dopiero początek możliwości AI w Twojej firmie!
Prawdopodobnie słyszałeś, że aby uzyskać wysokiej jakości wyniki z modeli generatywnych, kluczowe jest napisanie odpowiednich podpowiedzi. Polegając wyłącznie na krótkich i intuicyjnych podpowiedziach, szybko przekonasz się, że odpowiedzi generowane przez narzędzia są dość standardowe i powtarzalne. Prawdopodobnie nie zaspokoją one potrzeb Twojej firmy.
Dlatego następnym krokiem będzie wypróbowanie i eksperymentowanie z różnymi podpowiedziami. Pomoże ci to lepiej zrozumieć możliwości i ograniczenia systemów AI. Szybko poznasz też podstawowe cechy algorytmów AI:
Po wstępnych testach, które służą bardziej zabawie niż poważnym zastosowaniom, możesz zacząć tworzyć bardziej zaawansowane (ale wciąż szybkie w budowie) rozwiązania AI dla swojej firmy.
Może to obejmować stworzenie dobrej podpowiedzi (tj. instrukcji dla modela) i zapisanie jej do wielokrotnego użytku. Na przykład może to być instrukcja dotycząca postów w mediach społecznościowych, w której określasz styl swojej marki, wymagania dotyczące długości postów i możliwe użycie emotikonów lub hashtagów.
W wielu narzędziach (np. w Chat GPT) można również przesyłać pliki w różnych formatach - czy to arkusze kalkulacyjne (XLSX), dokumenty (PDF, DOCX), czy obrazy (JPG). W ten sposób zbudujesz agentów do zarządzania wiedzą w swojej firmie, na przykład w zakresie informacji o pracownikach lub szybkiego wyszukiwania informacji w celu udzielenia odpowiedzi klientowi.
Modele generatywne stanowią jedynie niewielką część szerokiej gamy dostępnych algorytmów sztucznej inteligencji. Prawdopodobnie nie wykorzystują one w pełni potencjału drzemiącego w danych gromadzonych przez firmę. Dlatego warto zapoznać się z innymi klasami modeli i rozważyć ich wykorzystanie w swojej firmie.
Pamiętaj, że korzystanie z tych modeli zazwyczaj wymaga zbudowania niestandardowego systemu AI przez zespół Data Science. Alternatywnie możesz zdecydować się na narzędzia o niskim kodzie lub bez kodu, w których osoby bez zaawansowanych umiejętności programistycznych mogą również tworzyć niestandardowe systemy sztucznej inteligencji.
Najważniejsze rodzaje niegeneratywnej ("tradycyjnej") sztucznej inteligencji obejmują:
Algorytmy te zazwyczaj przyjmują obrazy lub filmy jako dane wejściowe. Ich wyniki mogą obejmować klasyfikację i wykrywanie obiektów (na przykład identyfikowanie obiektów za pomocą kolorowych prostokątów) po segmentację semantyczną - wykrywanie całych obszarów obrazu i oznaczanie pikseli reprezentujących określone obiekty.
Przykład wykrywania i segmentacji obiektów: (https://manipulation.csail.mit.edu/segmentation.html)
Algorytmy przetwarzania obrazu znajdują szerokie zastosowanie w różnych branżach. W produkcji wykorzystywane są do kontroli jakości, monitorowania procesów produkcyjnych i zarządzania zasobami. W diagnostyce medycznej umożliwiają analizę zdjęć rentgenowskich, rezonansu magnetycznego i innych skanów, pomagając w szybkim wykrywaniu chorób i anomalii. Handel detaliczny wykorzystuje te technologie do analizy zachowań klientów, zarządzania zapasami i tworzenia spersonalizowanych ofert.
Systemy rekomendacji, mające kluczowe znaczenie w handlu elektronicznym, usługach streamingowych i marketingu cyfrowym, analizują preferencje i zachowania użytkowników w celu dostarczania spersonalizowanych rekomendacji dotyczących produktów, treści lub usług, zwiększając tym samym zaangażowanie i lojalność klientów.
Algorytmy predykcyjne analizują dane historyczne w celu prognozowania przyszłych zdarzeń, co jest nieocenione w sektorach takich jak finanse, logistyka i zarządzanie zasobami. Algorytmy klastrowania pomagają identyfikować wzorce i segmentować dane, co jest korzystne w analizie rynku i zarządzaniu klientami.
Systemy optymalizacji wykorzystują algorytmy sztucznej inteligencji do zarządzania procesami, zasobami i logistyką w możliwie najbardziej efektywny sposób. Mogą one znacznie obniżyć koszty operacyjne i zwiększyć wydajność biznesową. Przykłady obejmują zarządzanie magazynem, planowanie tras dostaw, planowanie produkcji, optymalizację wykorzystania maszyn i zasobów oraz redukcję odpadów.
Eksploracja tych różnorodnych możliwości sztucznej inteligencji może zapewnić wgląd w to, jak można je skutecznie zintegrować z procesami biznesowymi, zwiększając produktywność i podejmowanie decyzji w różnych dziedzinach.
Wykorzystanie potencjału sztucznej inteligencji w firmie może znacznie skorzystać na przeprowadzeniu warsztatów eksploracyjnych i kultywowaniu kultury sztucznej inteligencji. Inicjatywy te pomagają zespołom lepiej zrozumieć możliwości oferowane przez sztuczną inteligencję i sposób, w jaki technologie te można dostosować do konkretnych potrzeb biznesowych.
Warsztaty eksploracyjne to interaktywne sesje mające na celu zidentyfikowanie obszarów w firmie, w których sztuczna inteligencja może przynieść największe korzyści. Podczas tych warsztatów pracownicy z różnych działów współpracują, aby zrozumieć, jakie problemy można rozwiązać za pomocą sztucznej inteligencji i jakie nowe możliwości może ona otworzyć.
Wprowadzenie do warsztatów zazwyczaj rozpoczyna się od przeglądu podstawowych koncepcji AI, co pozwala uczestnikom lepiej zrozumieć pojęcia i terminologię. Następnie analizowane są konkretne przypadki użycia AI w branżach podobnych do Twojej firmy. W kolejnym etapie uczestnicy identyfikują własne wyzwania biznesowe i potrzeby, które można rozwiązać za pomocą sztucznej inteligencji, a następnie wspólnie opracowują wstępne pomysły na rozwiązania.
Budowanie kultury AI w firmie wymaga również stworzenia środowiska, które wspiera innowacje i ciągłe uczenie się. Kluczowe jest promowanie otwartości na nowe technologie i zachęcanie pracowników do eksperymentowania z narzędziami AI. Ponadto liderzy firmy powinni aktywnie wspierać inicjatywy związane ze sztuczną inteligencją i dawać przykład poprzez zaangażowanie w projekty wdrożeniowe AI.
Niestandardowe rozwiązania AI zazwyczaj wymagają znacznie większych inwestycji finansowych w porównaniu do prostych narzędzi AI, które często są darmowe lub kosztują kilkaset złotych miesięcznie. Koszt opracowania takich rozwiązań może wahać się od dziesiątek do setek tysięcy złotych.
Jeśli jednak masz dobrze zdefiniowany problem i Proof-of-Concept, który pokazuje, że system AI spełnia Twoje oczekiwania, korzyści mogą pojawić się szybko w postaci wzrostu sprzedaży o kilka do kilkudziesięciu procent, oszczędności na stratach, czy oszczędności tysięcy godzin pracy Twoich pracowników.
Sztuczna inteligencja w biznesie obejmuje szeroki zakres podejść. Pierwsze próby można rozpocząć na własną rękę, korzystając z gotowych narzędzi, które są darmowe lub bardzo tanie. Jeśli jednak szukasz czegoś bardziej zaawansowanego i dostosowanego do konkretnych potrzeb Twojej firmy, powinieneś przygotować się na wyższe koszty i skorzystać z pomocy ekspertów technicznych. Jeśli masz jakieś pytania lub chciałbyś przedyskutować swoje pomysły, skontaktuj się z nami!
Jednak w miarę jak modele stają się coraz bardziej złożone, może być trudno dowiedzieć się, co powoduje, że tworzą one określone prognozy. Dlatego też obserwujemy szybki wzrost liczby narzędzi interpretacyjnych, takich jak SHAP lub DALEX.
W tym artykule omówię kilka powodów, dla których interpretowalność jest tak ważna. Powodów jest więcej niż można by się spodziewać, a niektóre z nich są bardzo nieoczywiste.
Jednym z najważniejszych aspektów interpretowalności jest to, że pozwala ona zyskać zaufanie do modelu i mieć pewność, że robi on to, co powinien.
Pierwszym krokiem do oceny jakości modelu jest odpowiednio zdefiniowana metryka, w zależności od zastosowania - może to być np. dokładność, wynik f1 lub MAPE. Jednak nawet jeśli wybraliśmy odpowiednią metrykę, może ona zostać obliczona w niewłaściwy sposób lub może być nieinformatywna. Dlatego zazwyczaj możemy osiągnąć najwyższą pewność co do jakości modelu tylko poprzez zrozumienie, co robi i dlaczego daje takie prognozy.
W projektach Machine Learning zaufanie jest podstawą. Bez zaufania nie można budować relacji ani współpracy. Zaufanie pozwala współpracować i dzielić się danymi, wiedzą i doświadczeniem. Pozwala również na kontynuowanie współpracy w przyszłości.
Aby model był interpretowalny i godny zaufania, musi zawierać jasne wyjaśnienia tego, co robi i dlaczego to robi. Im bardziej przejrzysty jest wynik modelu, tym większe prawdopodobieństwo, że inni zaufają jego wynikom i będą chcieli ponownie z nim współpracować!
Zrozumienie modelu i sposobu jego działania jest niezwykle ważne, gdy wyniki modelu są poniżej oczekiwań i zaczynasz zastanawiać się, co się dzieje. Jeśli nie rozumiesz modelu, bardzo trudno jest debugować, jeśli coś pójdzie nie tak z wynikami prognoz.
Na przykład, jeśli algorytm nie daje dokładnych prognoz dla niektórych punktów danych w zestawie testowym, ale dobrze radzi sobie z innymi punktami danych, być może dobre punkty danych pochodzą z tego samego rozkładu, który był w zestawie treningowym. Kiedy zrozumiesz, na które cechy Twój model patrzy najczęściej, możesz odkryć, że być może błędne punkty danych są wartościami odstającymi z perspektywy tych cech. A może w tych punktach brakuje pewnych cech.
Dzięki możliwości interpretacji można dowiedzieć się, które cechy są ważne dla danego modelu i zaproponować prostsze modele alternatywne, które mają podobną moc predykcyjną.
Na przykład, załóżmy, że masz problem z klasyfikacją z tysiącami cech i odkrywasz, że tylko 10% z nich ma znaczenie w przewidywaniu rezygnacji klientów. Teraz wiesz, które cechy mają znaczenie, a które nie, więc może być możliwe usunięcie nieistotnych cech i ponowne wytrenowanie modelu. Będzie to szybsze, ponieważ ma mniej parametrów. Ale także proces gromadzenia i wstępnego przetwarzania danych będzie prostszy.
Narzędzia do wyjaśniania modelu pokazują nam cechy, które mają największy wpływ na wynik modelu. Niektóre relacje między cechami i korelacje z wynikami mogą być bardzo intuicyjne i znane ekspertom, np. jeśli próbujesz przewidzieć, czy klient nie spłaci pożyczki, historia jego spłaty może być ważnym czynnikiem. Jednak modele bardzo często wykrywają korelacje wcześniej niezbadane przez człowieka. Dzięki temu ludzkie decyzje mogą być w przyszłości lepsze, nawet jeśli nie zdecydujemy się na zastąpienie ich modelem.
Jeśli model jest wykorzystywany do określenia, czy można uzyskać zgodę na coś (pożyczkę, ubezpieczenie medyczne itp.), ważne jest, aby upewnić się, że model ma sens i zapewnia dokładną odpowiedź. Jeśli decyzja opiera się na nieprzejrzystej czarnej skrzynce, możesz nie mieć pojęcia, dlaczego jedna osoba została zatwierdzona, a inna nie. Ten brak przejrzystości oznacza również, że trudno będzie udowodnić, że model działa prawidłowo w sądzie, jeśli pojawią się problemy z jego prognozami w przyszłości.
Posiadanie interpretowalnego modelu jest ważne, aby mieć pewność, że model działa dobrze i budować zaufanie między Tobą a użytkownikami końcowymi. Jest to również ważne dla debugowania modelu, co może pomóc w szybkim wyizolowaniu problemów i naprawieniu ich przed wdrożeniem modelu w produkcji.
Wyjaśnienie modelu jest przydatne również wtedy, gdy nie będziesz korzystać z aktualnej wersji modelu - umożliwiając zbudowanie prostszej alternatywy lub poszerzając wiedzę ludzkich ekspertów i poprawiając ich decyzje.
Wreszcie, jeśli przechodzisz przez kontrole zgodności z przepisami, posiadanie interpretowalnej wersji modelu znacznie ułatwi te procedury.
Mam nadzieję, że ten artykuł okazał się przydatny w Twojej podróży do nauki o danych. Więcej artykułów znajdziesz na naszym blogu!
Projekt ma na celu opracowanie zaawansowanego systemu, który umożliwia wykrywanie usterek, zakłócenia i inne kwestie związane z infrastrukturą elektryczną, poprawiając w ten sposób jej bezpieczeństwo i wydajność.
1. Gromadzenie danych z kamer:
Nagrał setki godzin materiału wideo z dronów, koncentrując się na elektrycznych liniach przesyłowych.
2. Etykietowanie danych:
Adnotatorzy oznaczyli dane, zaznaczając różne obszary do monitorowania, w tym:
3. Wykorzystanie wstępnie wyszkolonych algorytmów AI:
Zastosowano wstępnie wytrenowane modele oparte na głębokim uczeniu i konwolucyjnych sieciach neuronowych (CNN).
4. Dostrajanie algorytmu:
Algorytmy zostały dostrojone do przewidywania zakłóceń w infrastrukturze elektrycznej poprzez szkolenie na oznaczonych danych.
5. Eksperymenty offline na danych historycznych:
Osiągnięto dokładność 92% na danych historycznych, służącą jako punkt wyjścia do dalszych ulepszeń.
6. Gromadzenie danych i walidacja algorytmów:
Zebrano dodatkowe dane i wykorzystano je do oceny algorytmu, osiągając dokładność 89,5%.
7. Iteracje w celu ulepszenia algorytmu:
Zastosowano techniki Ensemble, łącząc wyniki z różnych modeli, uzyskując dokładność 94%.
8. Praca nad redukcją rozmiaru modelu AI:
Aby umożliwić wdrożenie na urządzeniach docelowych, model został zoptymalizowany przy jednoczesnym zachowaniu jego skuteczności.
9. Pilotaż - wdrożenie algorytmu w dwóch lokalizacjach testowych:
Algorytm został przetestowany w warunkach rzeczywistych w dwóch lokalizacjach, umożliwiając ocenę i dostosowanie do różnych warunków terenowych.
10. Generowanie raportów z lotu drona:
Algorytm został zintegrowany z dronami, umożliwiając generowanie raportów z wynikami monitorowania po każdym locie drona.
Całkowity koszt projektu wyniósł 800 000 PLN i został podzielony w następujący sposób:


