In verschiedenen Berichten und Studien wird versucht, den Grad der KI‑Entwicklung und -Einführung im Unternehmenssektor zu erfassen.
Zu den umfassendsten Berichten, die bisher veröffentlicht wurden, gehören Stand der polnischen KI 2021 und Karte der polnischen AI 2019. Diese Berichte bieten eine umfangreiche Liste polnischer Unternehmen, auch solcher mit kleinen KI‑Teams. Leider hat sich in den letzten Jahren viel verändert, und es ist schade, dass diese Berichte nicht aktualisiert wurden.
Erwähnenswert ist die Liste der polnischen KI‑Startups die Mitte 2023 von Dr. Przemysław Chojecki zusammengestellt wurde und über 100 Start-ups sowie auf KI spezialisierte Dienstleistungsunternehmen - Softwarehäuser - umfasst. Eine ähnliche Liste der polnischen Start-upswurde von Jan Szumada erstellt.
Ein viel neuerer Bericht ist die EY‑Bericht: Wie setzen polnische Unternehmen KI ein?. EY befragte einen großen Querschnitt von Unternehmen (über 500) unterschiedlicher Größe und aus verschiedenen Branchen. Die wichtigste Schlussfolgerung: 20% der großen und mittleren Unternehmen in Polen haben KI-basierte Systeme implementiert, und 80% der Unternehmen, die die KI‑Implementierung abgeschlossen haben, geben an, Vorteile erzielt zu haben. Leider lassen diese Ergebnisse aufgrund der mangelnden Tiefe des Themas erhebliche Zweifel aufkommen - was genau verstehen wir unter “KI‑Implementierung”?
Medizinische Startups (170 aus Polen) werden in dem Bericht gründlich analysiert Top-Disruptoren im Gesundheitswesen. Dieser Bericht wurde von der AI in Health Coalition erstellt, der Unternehmen angehören (wie z. B. COGITA) und andere Einrichtungen, deren Ziel es ist, die Anwendung von künstlicher Intelligenz im Gesundheitswesen in Polen zum Nutzen von Patienten und Ärzten zu gestalten.
Eine vom Ministerium initiierte Plattform, ai4msp.pl, werden zahlreiche KI‑Projekte polnischer Unternehmen vorgestellt. Sie soll als Marktplatz dienen, obwohl es schwierig ist, ihre derzeitige Marktbedeutung zu beurteilen.
Podcasts und Interviews, wie z. B. Nieliniowy oder 99twarzyAI, geben einen recht guten Überblick darüber, was in polnischen Unternehmen tatsächlich mit künstlicher Intelligenz geschieht.
Es ist erwähnenswert, dass sich Unternehmen im Zeitalter der generativen KI zunehmend darauf konzentrieren, ihre eigenen Mitarbeiter (IT‑Abteilungen oder andere) zu schulen und KI‑Lösungen intern zu testen, anstatt die Arbeit an qualifizierte Datenwissenschaftler auszulagern, die bis vor kurzem ein Monopol auf die Entwicklung von Systemen für maschinelles Lernen und künstliche Intelligenz hatten.
Innerhalb des polnischen Verbands der Softwareunternehmen SoDA wurde eine Arbeitsgruppe für künstliche Intelligenz eingerichtet.SoDA AI Forschungsgruppewurde im vergangenen Jahr gegründet und besteht aus rund 100 Mitgliedern aus 30 polnischen KI‑Unternehmen.
Zwei von dieser Gruppe vorgelegte Berichte sind besonders erwähnenswert. Mensch-KI‑Zusammenarbeit: Perspektiven für den polnischen öffentlichen Sektor enthält Beispiele für KI‑Projekte, die in verschiedenen Bereichen des öffentlichen Sektors durchgeführt wurden, und die damit verbundenen Herausforderungen. Inzwischen hat der Bericht Generative KI in der Wirtschaft (der nicht nur von SoDA mitgestaltet wurde) konzentriert sich ausschließlich auf generative künstliche Intelligenz und stellt deren Potenzial in verschiedenen Branchen vor. Dieser Bericht konzentriert sich eher auf die Vorstellung von Möglichkeiten und Werkzeugen als auf die Präsentation tatsächlich realisierter KI‑Projekte.
In den letzten Monaten hat die Kammer AI Außerdem wurde eine Handelskammer gegründet, in der derzeit 44 Unternehmen gelistet sind, die sich mit KI‑Lösungen beschäftigen.
In den letzten anderthalb Jahren ist das Interesse an künstlicher Intelligenz auch bei Nichttechnikern, Programmierern, die sich bisher mit anderen Technologien befasst haben, und Personen, die ihr eigenes Unternehmen aufbauen, enorm gestiegen.
Verschiedene Gruppen haben bemerkenswerte Schulungen, Gemeinschaften und Plattformen geschaffen, wie z. B. Elefant AI, AI_Devs, Campus AI, oder Aufbau von AI‑Produkten. Das Niveau und die Ergebnisse dieser Kurse sind sehr unterschiedlich, was oft dazu führt, dass die Teilnehmer an mehreren verschiedenen Schulungen teilnehmen. Einige Kurse haben Tausende von Teilnehmern.
Was die Branchenveranstaltungen betrifft, so nehmen die seit langem bestehenden zyklischen, eher technischen Initiativen weiter zu, wie z. B. Gipfel der Datenwissenschaft, ML in PL, PyData, oder warschau.ai. Es entstehen aber auch immer mehr lokale Initiativen für KI‑Begeisterte, wie z. B. AI‑Frühstücke, Masowisches AI‑Fest, oder GenAI Krakau.
In dieser Kategorie sind die SpeakLeash Community, die mehr als 1.000 Enthusiasten umfasst, die sich der Idee verschrieben haben, einen großen Korpus polnischer Sprachdaten zu erstellen, der dann zum Training polnischer LLMs verwendet wird, ist ebenfalls erwähnenswert.
Eine großartige Analyse dessen, was in der polnischen Wissenschaft im Bereich der KI geschieht, wird in der IDEAS NCBR‑Bericht “Die Besten halten - Trends in der Doktorandenausbildung im Bereich der Künstlichen Intelligenz”. Daraus geht hervor, dass in den letzten 3,5 Jahren in Polen nur 200 Doktorarbeiten im Bereich der KI verteidigt wurden. Angesichts der rasanten Entwicklung in diesem Bereich ist das eine geringe Zahl.
Es ist erwähnenswert, dass in einer Ära des raschen Wandels, der durch KI vorangetrieben wird, Autoritäten auf diesem Gebiet oft Personen mit einer Ausbildung in anderen Bereichen (Philosophie, Management) oder Prominente sind. Diese Personen gewinnen mit ihren lautstarken Marketingbotschaften ein großes Publikum und bieten ihre Auftritte bei Konferenzen, Beratungen oder Schulungen an.
Ein Beispiel für eine Liste, in der versucht wurde, die einflussreichsten Personen in der KI auszuwählen, ist der Artikel “Die 23 einflussreichsten Polen in der KI” vorbereitet von MyCompany Polska.
Im Bereich der KI sind auch staatliche und internationale Initiativen zu nennen. Seit 2016 wird die Entwicklung des KI‑Strategie wurde fortgesetzt, wobei der Meilenstein die Annahme des “Politik für die Entwicklung der künstlichen Intelligenz in Polen ab 2020″.. Dieses Dokument blieb jedoch in der polnischen Wirtschaft weitgehend unbemerkt, so dass es schwierig ist, seine Rolle bei der Gestaltung der KI-bezogenen Realität zu beurteilen.
Es scheint, dass die Umsetzung des EU‑AI‑Gesetzes, dessen Die vor kurzem abgeschlossenen Vorabkonsultationen werden eine viel wichtigere Rolle spielen.
Seit 2018 betreibt das Digitalisierungsministerium ein Arbeitsgruppe für künstliche Intelligenz, Aber trotz des breiten Querschnitts von Spezialisten und mehrerer Berichte ist es schwierig, einen breiteren Einfluss dieser Gruppe auf die KI-bezogene Realität in Polen zu erkennen.
Gewiss, öffentliche Finanzierungsprogramme wie Ścieżka Smart spielen eine wichtige Rolle bei der Entwicklung von Unternehmen, auch wenn sie im Vergleich zu den für die KI‑Entwicklung in anderen Ländern bereitgestellten Mitteln unzureichend erscheinen.
Herkömmliche Qualitätskontrollmethoden sind oft zeitaufwändig und anfällig für menschliche Fehler, was zu Ineffizienzen und erhöhten Kosten führt. In diesem Artikel stellen wir eine hypothetische Fallstudie vor, die zeigt, wie ein fortschrittliches Bilderkennungssystem die Qualitätskontrolle in der Lebensmittelindustrie am Beispiel eines großen Obst- und Gemüseverarbeitungsunternehmens revolutionieren kann.
Das Unternehmen ist auf die Herstellung von Konfitüren, Säften, Gemüsekonserven und Tiefkühlkost spezialisiert. Es verarbeitet täglich Tausende von Tonnen an Rohstoffen auf seinen umfangreichen Produktionsanlagen. Die größte Herausforderung für das Unternehmen besteht darin, eine hohe Produktqualität aufrechtzuerhalten, den Ausschuss zu minimieren und Produktionsfehler wie Verunreinigungen, mechanische Beschädigungen von Obst und Gemüse sowie die Nichteinhaltung von Qualitätsstandards schnell zu erkennen. Herkömmliche Qualitätskontrollmethoden erwiesen sich als unzureichend, so dass das Unternehmen ein KI-basiertes automatisches Bilderkennungssystem einführte.
Ziel des Projekts war es, ein fortschrittliches KI‑System zu entwickeln und zu implementieren, das Lebensmittelprodukte in der Produktionslinie automatisch prüft und Mängel und Schäden erkennt. Das System sollte die Effizienz der Qualitätskontrolle durch die Automatisierung des Prozesses erhöhen, die Produktionsabfälle durch die schnelle Erkennung von Mängeln verringern und die Gesamtqualität der an den Markt gelieferten Produkte verbessern, was zu einer höheren Kundenzufriedenheit führt.
Drei Monate vor dem Projekt installierte das Unternehmen Kameras an den wichtigsten Stellen der Produktionslinie. Die Kameras wurden an der Rohwarenannahme, an den Sortieranlagen und an den Verpackungsmaschinen installiert. Diese strategischen Standorte ermöglichten die Überwachung der Qualität von Rohstoffen und Produkten in verschiedenen Produktionsstadien. Die Kameras erfassten Bilder von Rohstoffen wie Äpfeln, Tomaten, Paprika, Karotten und Kartoffeln, die dann auf Mängel und Schäden analysiert wurden.
Im Laufe von drei Monaten sammelte das Unternehmen etwa 500.000 Bilddatensätze, wobei täglich etwa 5.000 neue Bilder hinzukamen. Diese Daten wurden auf lokalen Servern und in der Cloud gespeichert, um einen einfachen Zugriff auf große Datensätze zu gewährleisten. Jeder Datensatz enthielt einen Zeitstempel, den Standort an der Produktionslinie, den Produkttyp und eine Beschreibung des Fehlers, falls dieser entdeckt wurde. Während der Datenerfassung wurden einige Kameramethoden und -standorte geändert, um die Qualität der erfassten Daten zu verbessern. Fehlende Daten wurden durch zusätzliche Fotositzungen und Verbesserungen der Kamerakonfiguration ergänzt.
Für die Systemimplementierung wurden fortschrittliche KI‑Technologien und -Tools wie Pytorch und OpenCV verwendet. Convolutional Neural Networks (CNNs) wurden aufgrund ihrer Effektivität bei Bildanalyseaufgaben ausgewählt, da sie in der Lage sind, automatisch Merkmale und Muster zu erkennen. Außerdem wurde Transfer-Lernen eingesetzt, wobei das vortrainierte YOLO‑Modell verwendet wurde, das an die spezifischen Daten der Lebensmittelindustrie angepasst wurde.
Die Bilddaten wurden mit OpenCV vorverarbeitet, einschließlich Farbkorrektur, Lichtnormalisierung und Rauschentfernung. Um den Trainingsdatensatz zu vergrößern und die Modellgeneralisierung zu verbessern, wurden Datenerweiterungen wie Rotation, Skalierung und Änderungen von Helligkeit und Kontrast vorgenommen. Die CNN‑Modelle wurden auf großen Bilddatensätzen trainiert, die verschiedene Klassen von Rohstoffen und verschiedene Arten von Defekten abdecken. Der Trainingsprozess wurde durch den Einsatz von Grafikprozessoren mit NVIDIA CUDA‑Technologie beschleunigt, was eine effiziente Verarbeitung großer Datensätze ermöglicht.
Das Bilderkennungsmodell wurde auf AWS‑Servern mit GPU‑Unterstützung bereitgestellt, um eine schnelle Bilddatenverarbeitung zu gewährleisten. Für die Skalierung und Systemleistung wurden AWS EC2‑Server mit p3.2xlarge-Instanzen verwendet. Mit Flask wurde eine RESTful-API erstellt, die die Kommunikation zwischen dem Bilderkennungssystem und der Produktionslinie ermöglicht. Die API verarbeitete HTTP‑POST‑Anfragen zum Senden von Bildern und Empfangen von Analyseergebnissen.
Die API wurde in das bestehende Produktionssystem des Unternehmens integriert und ermöglichte die automatische Bildübertragung von den Kameras zum Bilderkennungssystem. Das Produktionssystem sendete die Bilder in Echtzeit an die API, und die Analyseergebnisse wurden an das Produktionssystem zurückgesendet, damit entsprechende Maßnahmen ergriffen werden konnten, z. B. das Entfernen defekter Produkte aus der Linie.
Überwachungs- und Verwaltungstools wie Amazon CloudWatch wurden implementiert, um eine kontinuierliche Systemverfügbarkeit und -leistung zu gewährleisten.

Das System erreichte eine Genauigkeit von 80% bei der Erkennung von Rohmaterialfehlern, was dem Hersteller erhebliche geschäftliche Vorteile einbrachte. Die Implementierung reduzierte den Produktionsabfall um 20%, was 10 Tonnen weniger Abfall pro Monat entspricht.
Die Effizienz der Qualitätskontrolle von Rohstoffen stieg um 50%, was zu schnelleren und genaueren Inspektionen führte. Wenn man davon ausgeht, dass die mit der Qualitätskontrolle von Rohstoffen verbundenen Arbeitskosten 50.000 PLN pro Monat betragen, belaufen sich die Einsparungen durch die erhöhte Effizienz auf 25.000 PLN pro Monat.
An dem Projekt waren drei Data Scientists und ein Teilzeit-Projektmanager beteiligt. Es dauerte vier Monate und umfasste die Datenaufbereitung, die Modellschulung und die Systembereitstellung.
AWS‑Server wurden für das Modelltraining und die Bereitstellung des Bilderkennungssystems verwendet. Die Modellschulung auf EC2 p3.2xlarge-Instanzen kostete 10.600 PLN für 900 Arbeitsstunden. Bereitstellung und Betrieb auf EC2 t3.large-Instanzen kosteten 900 PLN für 4 Monate Arbeit. Die Datenspeicherung auf Amazon S3 kostete 700 PLN für 2 TB Daten über 4 Monate, und die Verwendung von Amazon RDS für die Datenbankspeicherung kostete 1.100 PLN.
Die Gesamtkosten des Projekts beliefen sich auf 513.300 PLN.
Das System wurde mit Amazon CloudWatch auf Verfügbarkeit und Leistung überwacht, und die Bilderkennungsmodelle wurden regelmäßig monatlich aktualisiert, um Änderungen bei den Rohstoffen und neuen Fehlertypen Rechnung zu tragen. Ein Warnsystem informierte das Team über alle Unregelmäßigkeiten wie Leistungsabfälle oder Probleme mit der Datenverfügbarkeit.
Die Zusammenarbeit zwischen den Teams war entscheidend für den Erfolg des Projekts. Es fanden regelmäßige Treffen zwischen den Teams für Datenwissenschaft, IT, Produktion und Qualitätsmanagement statt, um den Projektfortschritt zu besprechen, Ideen auszutauschen und mögliche Probleme zu identifizieren. Alle Projektphasen wurden sorgfältig dokumentiert, einschließlich der technischen Spezifikationen, Datenanalyseberichte, A/B‑Testergebnisse und Empfehlungen für weitere Maßnahmen. Für das Produktionsteam wurden Schulungen zur Verwendung des Bilderkennungssystems und zur Interpretation der Ergebnisse durchgeführt, um das Potenzial des Tools zu maximieren.
Das Projekt war mit mehreren Herausforderungen konfrontiert, wie z. B. der Sicherstellung der Skalierbarkeit des Systems zur Bewältigung wachsender Daten- und Rohstoffmengen und der kontinuierlichen Verbesserung der Genauigkeit des Erkennungsmodells durch regelmäßige Updates und Algorithmusoptimierung. Die Integration mit verschiedenen Produktionssystemen und die Gewährleistung der Kompatibilität stellten ebenfalls eine Herausforderung dar.
Für die Zukunft plant der Lebensmittelhersteller, den Erkennungsumfang zu erweitern und die Erkennung anderer Fehlertypen, wie strukturelle Verformungen oder Farbveränderungen, einzuführen. Die nächsten Schritte in der Systementwicklung sind eine stärkere Automatisierung durch fortschrittlichere Entscheidungsfindungsmechanismen an der Produktionslinie und die Nutzung fortschrittlicher Analysen zur Vorhersage von Qualitätsproblemen und zur Optimierung von Produktionsprozessen.
Die Einführung eines fortschrittlichen Bilderkennungssystems brachte erhebliche Vorteile mit sich, z. B. die Verringerung der Produktionsabfälle, die Steigerung der Effizienz der Qualitätskontrolle von Rohstoffen und die Verbesserung der Produktqualität. Obwohl das Projekt mit einigen Herausforderungen konfrontiert war, waren die geschäftlichen Vorteile der Implementierung des Systems beträchtlich, und das Unternehmen plant für die Zukunft eine weitere Entwicklung und Optimierung des Systems.
Diese hypothetische Fallstudie zeigt, wie künstliche Intelligenz die Lebensmittelbranche revolutionieren und sowohl den Herstellern als auch den Verbrauchern spürbare Vorteile bringen kann.
Online-Shops müssen ihr Angebot ständig an die Bedürfnisse und Vorlieben der Kunden anpassen, um die Konversionsraten und den Warenkorbwert zu erhöhen.
Im Folgenden werden wir Schritt für Schritt ein hypothetisches Projekt zur Implementierung eines fortschrittlichen Empfehlungssystems in einem Elektronikmarkt erörtern, das die Verkaufszahlen und das Einkaufserlebnis der Kunden erheblich verbessern könnte.
Ein auf Elektronik (Laptops, Smartphones, Fernseher und Zubehör) spezialisiertes Online-Geschäft stellte fest, dass viele Kunden die Website verließen, ohne einen Kauf zu tätigen. Trotz einer breiten Produktpalette hatten die Nutzer Schwierigkeiten, Artikel zu finden, die ihren Bedürfnissen entsprachen. Infolgedessen waren die Konversionsraten und der durchschnittliche Warenkorbwert niedriger als erwartet, was sich negativ auf den Umsatz und die Rentabilität des Shops auswirkte.
Das Projekt zielte darauf ab, ein fortschrittliches Empfehlungssystem zu entwickeln und zu implementieren:
Das Projekt nutzte verschiedene Datenquellen, die für die erfolgreiche Implementierung des Empfehlungssystems entscheidend sind:
Um die Datenqualität zu gewährleisten, wurden Maßnahmen ergriffen:
Datenaufbereitung und -verarbeitung
Vor der Entwicklung des Empfehlungssystems wurden mehrere Maßnahmen ergriffen, um wertvolle Geschäftserkenntnisse zu gewinnen:
Bei der Implementierung des Empfehlungssystems wurden verschiedene Modelle und Technologien der künstlichen Intelligenz eingesetzt:
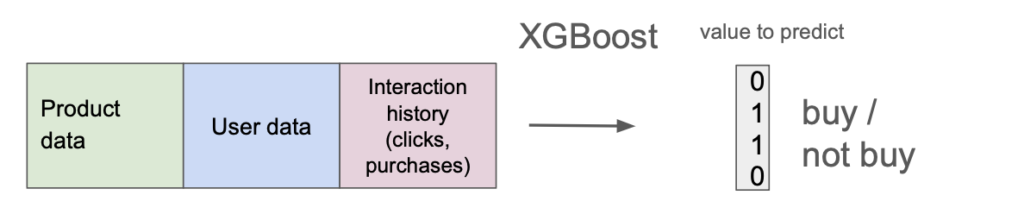
Nachdem das System implementiert war, wurden A/B‑Tests durchgeführt. Das Empfehlungssystem lieferte seine Ergebnisse für 50% zufällig ausgewählte Nutzer, während der Rest die übliche Produktreihenfolge (nach Beliebtheit) erhielt. Dies ermöglichte eine genaue Messung der Qualität des Modells.
Die Hauptkosten des Projekts waren die Löhne des Entwicklungsteams.
Projektdauer: 2 Monate.
Da das gesamte System in der Cloud implementiert wurde, fielen zusätzliche Kosten an:
Gesamtkosten des Projekts: 303.870 PLN.
So hat sich die Investition bereits zwei Wochen nach der Einführung der Lösung ausgezahlt.
Nach der Implementierung des maschinellen Lernmodells war es wichtig, seine Leistung zu überwachen und die notwendigen Anpassungen vorzunehmen.
Die Überwachung wurde mit Amazon CloudWatch durchgeführt. Aufgrund der Einführung neuer Produkte und sich ändernder Benutzerpräferenzen wurde ein automatisches wöchentliches Modelltraining eingeführt. Außerdem wurde ein Warnsystem eingeführt, um Anomalien zu melden.
Für jedes empfohlene Produkt konnten die Nutzer einen Daumen hoch oder runter klicken, um die Qualität der Empfehlung zu bewerten. Dies lieferte eine zusätzliche Informationsquelle, die für die Nachschulung des KI‑Modells nützlich war.
Die hypothetische Implementierung eines fortschrittlichen Empfehlungssystems in einem Elektronikmarkt war ein wichtiger Schritt zur Verbesserung des Einkaufserlebnisses der Kunden und zur Steigerung der Verkaufseffizienz.
Durch die Personalisierung des Produktangebots auf der Grundlage der Nutzerpräferenzen wurden spürbare Verbesserungen bei den Konversionsraten und dem durchschnittlichen Warenkorbwert erzielt.
Das Projekt erforderte die Integration von Daten aus verschiedenen Quellen und die Anwendung fortschrittlicher Technologien des maschinellen Lernens, wie XGBoost, die eine effektive Verarbeitung und Analyse großer Datenmengen und die Erstellung präziser Produktempfehlungen in Echtzeit ermöglichten.
In den letzten Jahren haben wir mehrere bahnbrechende Momente erlebt, wie die Schaffung des AlphaZero-Modells im Jahr 2017, das in Schach und Go Großmeister-Niveau erreichte, und die Entwicklung der Transformer-Architektur im selben Jahr, die zahlreichen Sprachverarbeitungsmodellen zugrunde liegt. Mit der Veröffentlichung des GPT-3.5‑Modells als Chatbot, ChatGPT, am 30. November 2022 rückte KI jedoch in den Blickpunkt der Öffentlichkeit. Der Einsatz von KI hat sich im Privatleben und bei der Suche nach Geschäftsanwendungen zur Zeitersparnis, Rationalisierung von Prozessen und Gewinnsteigerung durchgesetzt.
Es ist wichtig, darauf hinzuweisen, dass der Einsatz von KI-basierten Algorithmen (genauer gesagt, maschinelles Lernen) für Geschäftsanwendungen seit mindestens einigen Jahren im Gange ist. Gängige Beispiele sind Systeme, die Internetnutzern Werbung oder andere Inhalte empfehlen, prädiktive Systeme in Finanzinstituten und Bilderkennungsalgorithmen in der Industrie. Obwohl sich diese Algorithmen ständig weiterentwickeln, sind die Unternehmen noch weit davon entfernt, das Potenzial der KI voll auszuschöpfen.
Daher werde ich in diesem Artikel nicht nur darlegen, wie Sie generative künstliche Intelligenz (wie ChatGPT oder Midjourney) in Ihrem Unternehmen einsetzen können, sondern auch allgemeiner beschreiben, wie Sie Bereiche identifizieren, die durch verschiedene Arten von KI‑Algorithmen verbessert werden können.
Es lohnt sich, die Reise in die KI mit einem Blick auf die verfügbaren Tools zu beginnen. Es gibt bereits eine ganze Reihe davon, die jeweils sehr unterschiedliche Anwendungen bedienen. Hier sind einige Beispiele.
Adobe Firefly ist ein fortschrittliches Werkzeug zur Erstellung und Bearbeitung von Grafiken, ideal für Marketing- und Designabteilungen. Mit Synthesia hingegen können Sie Videos mit generierten Stimmen und Charakteren erstellen, was eine großartige Lösung für die Erstellung von Schulungsmaterialien und Präsentationen ist.
ChatGPT und Gemini sind vielseitige Tools, die Ihnen bei der Erstellung von Marketinginhalten, beim Kundenservice, bei der Beantwortung von E‑Mails oder bei der Ideenfindung helfen können. Grammarly wiederum hilft bei der Verbesserung der Grammatik und des Schreibstils, was bei der Erstellung hochwertiger Marketinginhalte und Berichte von unschätzbarem Wert ist.
Turbologo und Logopony sind Tools zur Logogenerierung, die den Prozess der Erstellung der visuellen Identität Ihres Unternehmens beschleunigen können. Canva bietet eine breite Palette von Design-Tools, darunter auch solche, die generative KI‑Modelle verwenden. Mit Midjourney oder Leonardo.ai können Sie hochwertige Grafiken erstellen. Wenn Sie Hintergrundmusik benötigen, sollten Sie sich Suno ansehen.
Tools wie Slides AI, Presentations AI, Pitch und Beautiful.AI ermöglichen die Erstellung attraktiver Präsentationen mit automatischer Formatierung, was eine erhebliche Zeitersparnis und eine Verbesserung der visuellen Qualität der präsentierten Materialien mit sich bringt.
Vergessen Sie nicht, Meeting-Transkriptionstools wie OtterAI und Textzusammenfassungssysteme wie SummarizeBot zu verwenden.
Für Forschungsteams bietet Scite.AI erweiterte Funktionen für die Suche nach wissenschaftlichen Informationen und beschleunigt den Forschungsprozess erheblich.
Es lohnt sich, mit verschiedenen Tools zu experimentieren, um diejenigen zu finden, die den Bedürfnissen Ihres Unternehmens am besten entsprechen. Sie werden sicherlich die Effizienz Ihrer Mitarbeiter steigern. Der Einsatz dieser Tools ist jedoch nur der Anfang der KI‑Möglichkeiten in Ihrem Unternehmen!
Sie haben wahrscheinlich schon gehört, dass es für qualitativ hochwertige Ergebnisse von generativen Modellen entscheidend ist, geeignete Prompts zu schreiben. Wenn Sie sich nur auf kurze und intuitive Prompts verlassen, werden Sie schnell feststellen, dass die von den Tools generierten Antworten ziemlich standardisiert und repetitiv sind. Sie entsprechen wahrscheinlich nicht den Anforderungen Ihres Unternehmens.
Der nächste Schritt besteht daher darin, verschiedene Aufforderungen auszuprobieren und mit ihnen zu experimentieren. Dies wird Ihnen helfen, die Fähigkeiten und Grenzen von KI‑Systemen besser zu verstehen. Sie werden auch schnell die grundlegenden Eigenschaften von KI‑Algorithmen kennenlernen:
Nach anfänglichen Versuchen, die eher dem Spaß als ernsthaften Anwendungen dienen, können Sie mit der Entwicklung fortgeschrittener (aber immer noch schnell zu erstellender) KI‑Lösungen für Ihr Unternehmen beginnen.
Dazu könnte es gehören, eine gute Aufforderung (d. h. eine Anweisung für das Modell) zu erstellen und sie für die wiederholte Verwendung zu speichern. Dies könnte zum Beispiel eine Anleitung für Beiträge in sozialen Medien sein, in der Sie den Stil Ihrer Marke, die Anforderungen an die Länge der Beiträge und die mögliche Verwendung von Emojis oder Hashtags festlegen.
In vielen Tools (z. B. in Chat GPT) können Sie auch Dateien in verschiedenen Formaten hochladen, z. B. Tabellenkalkulationen (XLSX), Dokumente (PDF, DOCX) oder Bilder (JPG). Auf diese Weise bauen Sie Agenten auf, die das Wissen in Ihrem Unternehmen verwalten, z. B. in Bezug auf Mitarbeiterinformationen oder die schnelle Suche nach Informationen, um einem Kunden zu antworten.
Generative Modelle stellen nur einen kleinen Teil des breiten Spektrums der verfügbaren KI‑Algorithmen dar. Wahrscheinlich schöpfen sie das Potenzial der von Ihrem Unternehmen gesammelten Daten nicht vollständig aus. Daher lohnt es sich, andere Modellklassen zu untersuchen und ihren Einsatz in Ihrem Unternehmen zu prüfen.
Denken Sie daran, dass die Verwendung dieser Modelle in der Regel die Erstellung eines maßgeschneiderten KI‑Systems durch ein Data-Science-Team erfordert. Alternativ können Sie sich für Low-Code- oder No-Code-Tools entscheiden, mit denen auch Personen ohne fortgeschrittene Programmierkenntnisse maßgeschneiderte KI‑Systeme erstellen können.
Zu den wichtigsten Arten der nicht-generativen ("traditionellen") KI gehören:
Diese Algorithmen verwenden in der Regel Bilder oder Videos als Eingabe. Ihre Ergebnisse können von der Klassifizierung und Objekterkennung (z. B. Identifizierung von Objekten anhand farbiger Rechtecke) bis hin zur semantischen Segmentierung reichen, d. h. der Erkennung ganzer Bereiche eines Bildes und der Kennzeichnung von Pixeln, die bestimmte Objekte darstellen.
Beispiel für die Erkennung und Segmentierung von Objekten: (https://manipulation.csail.mit.edu/segmentation.html)
Bildverarbeitungsalgorithmen finden in verschiedenen Branchen breite Anwendung. In der Fertigung werden sie für die Qualitätskontrolle, die Überwachung von Produktionsprozessen und das Ressourcenmanagement eingesetzt. In der medizinischen Diagnostik ermöglichen sie die Analyse von Röntgenbildern, MRTs und anderen Scans und helfen bei der schnellen Erkennung von Krankheiten und Anomalien. Der Einzelhandel nutzt diese Technologien zur Analyse des Kundenverhaltens, zur Bestandsverwaltung und für personalisierte Angebote.
Empfehlungssysteme, die im E‑Commerce, bei Streaming-Diensten und im digitalen Marketing eine wichtige Rolle spielen, analysieren die Vorlieben und das Verhalten der Nutzer, um personalisierte Empfehlungen für Produkte, Inhalte oder Dienstleistungen zu geben und so die Kundenbindung zu erhöhen.
Prädiktive Algorithmen analysieren historische Daten, um zukünftige Ereignisse vorherzusagen, was in Bereichen wie Finanzen, Logistik und Ressourcenmanagement von unschätzbarem Wert ist. Clustering-Algorithmen helfen bei der Identifizierung von Mustern und der Segmentierung von Daten, was bei der Marktanalyse und der Kundenverwaltung von Vorteil ist.
Optimierungssysteme nutzen KI‑Algorithmen, um Prozesse, Ressourcen und Logistik so effizient wie möglich zu verwalten. Sie können die Betriebskosten erheblich senken und die Unternehmenseffizienz steigern. Beispiele sind Lagerverwaltung, Routenplanung für Lieferungen, Produktionsplanung, Optimierung der Maschinen- und Ressourcennutzung und Abfallreduzierung.
Die Erforschung dieser verschiedenen KI‑Funktionen kann Aufschluss darüber geben, wie sie effektiv in Ihre Geschäftsprozesse integriert werden können, um die Produktivität und Entscheidungsfindung in verschiedenen Bereichen zu verbessern.
Die Durchführung von Sondierungsworkshops und die Pflege einer KI‑Kultur können für die Nutzung des Potenzials der KI in Ihrem Unternehmen von großem Nutzen sein. Diese Initiativen helfen den Teams, die von KI gebotenen Möglichkeiten besser zu verstehen und herauszufinden, wie diese Technologien an spezifische Geschäftsanforderungen angepasst werden können.
Sondierungsworkshops sind interaktive Sitzungen, in denen ermittelt werden soll, in welchen Bereichen des Unternehmens künstliche Intelligenz den größten Nutzen bringen kann. In diesen Workshops arbeiten Mitarbeiter aus verschiedenen Abteilungen zusammen, um zu verstehen, welche Probleme mithilfe von KI gelöst werden können und welche neuen Möglichkeiten KI eröffnen kann.
Die Einführung in die Workshops beginnt in der Regel mit einem Überblick über die grundlegenden KI‑Konzepte, damit die Teilnehmer die Konzepte und die Terminologie besser verstehen können. Anschließend werden konkrete Anwendungsfälle von KI in Branchen, die denen Ihres Unternehmens ähneln, analysiert. Im nächsten Schritt identifizieren die Teilnehmer ihre eigenen geschäftlichen Herausforderungen und Bedürfnisse, die mit KI angegangen werden können, und entwickeln dann gemeinsam erste Ideen für Lösungen.
Der Aufbau einer KI‑Kultur im Unternehmen erfordert auch die Schaffung eines Umfelds, das Innovation und kontinuierliches Lernen unterstützt. Es ist entscheidend, die Offenheit gegenüber neuen Technologien zu fördern und die Mitarbeiter zu ermutigen, mit KI‑Tools zu experimentieren. Darüber hinaus sollten Unternehmensleiter KI-bezogene Initiativen aktiv unterstützen und durch die Beteiligung an KI‑Implementierungsprojekten mit gutem Beispiel vorangehen.
Maßgeschneiderte KI‑Lösungen erfordern in der Regel viel größere finanzielle Investitionen als einfache KI‑Tools, die oft kostenlos sind oder einige hundert Złotys pro Monat kosten. Die Kosten für die Entwicklung solcher Lösungen können zwischen zehn- und hunderttausenden von Złotys liegen.
Wenn Sie jedoch ein klar definiertes Problem und einen Proof-of-Concept haben, der zeigt, dass das KI‑System Ihre Erwartungen erfüllt, können sich die Vorteile schnell in Form von Umsatzsteigerungen von mehreren bis mehreren Dutzend Prozent, Einsparungen bei Verlusten oder Einsparungen von Tausenden von Arbeitsstunden für Ihre Mitarbeiter zeigen.
Künstliche Intelligenz in der Wirtschaft umfasst ein breites Spektrum von Ansätzen. Sie können mit ersten Versuchen auf eigene Faust beginnen, indem Sie vorgefertigte Tools verwenden, die kostenlos oder sehr kostengünstig sind. Wenn Sie jedoch nach etwas Fortgeschrittenem suchen, das auf die spezifischen Bedürfnisse Ihres Unternehmens zugeschnitten ist, sollten Sie sich auf höhere Kosten einstellen und die Hilfe von technischen Experten in Anspruch nehmen. Wenn Sie Fragen haben oder Ihre Ideen weiter besprechen möchten, wenden Sie sich bitte an uns!
Da die Modelle jedoch immer komplexer werden, kann es schwierig sein, herauszufinden, was sie dazu veranlasst, bestimmte Vorhersagen zu treffen. Deshalb beobachten wir eine rasche Zunahme von Interpretationswerkzeugen wie SHAP oder DALEX.
In diesem Artikel werde ich einige Gründe erörtern, warum Interpretierbarkeit so wichtig ist. Es gibt mehr Gründe, als man erwarten könnte, und einige von ihnen sind nicht so offensichtlich.
Einer der wichtigsten Aspekte der Interpretierbarkeit ist, dass Sie dadurch Vertrauen in Ihr Modell gewinnen und sicher sein können, dass es das tut, was es tun soll.
Der erste Schritt bei der Bewertung der Modellqualität ist die Festlegung einer geeigneten Metrik, die je nach Anwendung z. B. Genauigkeit, f1‑Score oder MAPE sein kann. Doch selbst wenn Sie die richtige Metrik gewählt haben, kann sie falsch berechnet werden oder nicht aussagekräftig sein. Daher können wir in der Regel das höchste Vertrauen in die Qualität des Modells nur erreichen, wenn wir verstehen, was es tut und warum es solche Vorhersagen macht.
Bei Projekten zum maschinellen Lernen ist Vertrauen die Grundlage. Ohne Vertrauen kann man keine Beziehungen oder Kooperationen aufbauen. Vertrauen ermöglicht es Ihnen, zusammenzuarbeiten und Daten, Wissen und Erfahrung auszutauschen. Außerdem ermöglicht es Ihnen, auch in Zukunft miteinander zu arbeiten.
Damit Ihr Modell interpretierbar und vertrauenswürdig ist, muss es klare Erklärungen enthalten, was es tut und warum es es tut. Je transparenter Sie die Ergebnisse Ihres Modells machen können, desto wahrscheinlicher ist es, dass andere Ihren Ergebnissen vertrauen - und wieder mit Ihnen zusammenarbeiten wollen!
Das Verständnis des Modells und seiner Funktionsweise ist äußerst wichtig, wenn die Ergebnisse des Modells hinter Ihren Erwartungen zurückbleiben und Sie herausfinden wollen, was los ist. Wenn Sie das Modell nicht verstehen, ist es sehr schwierig, Fehler zu beheben, wenn etwas mit Ihren Vorhersageergebnissen schief läuft.
Wenn ein Algorithmus beispielsweise für einige Datenpunkte in einem Testsatz keine genauen Vorhersagen macht, aber bei anderen Datenpunkten gut abschneidet, stammen die guten Datenpunkte vielleicht aus der gleichen Verteilung wie im Trainingssatz. Wenn Sie verstehen, auf welche Merkmale Ihr Modell am meisten achtet, können Sie feststellen, dass falsche Datenpunkte vielleicht Ausreißer aus der Perspektive dieser Merkmale sind. Oder vielleicht fehlen in diesen Punkten einige Merkmale.
Dank der Interpretierbarkeit können Sie wissen, welche Merkmale für Ihr Modell wichtig sind, und einfachere Alternativmodelle vorschlagen, die eine ähnliche Vorhersagekraft haben.
Angenommen, Sie haben ein Klassifizierungsproblem mit Tausenden von Merkmalen und stellen fest, dass nur 10% von ihnen für die Vorhersage der Kundenabwanderung von Bedeutung sind. Da Sie nun wissen, welche Merkmale wichtig sind und welche nicht, können Sie möglicherweise unwichtige Merkmale entfernen und Ihr Modell erneut trainieren. Das wird schneller gehen, weil es weniger Parameter hat. Aber auch der Prozess der Datenerfassung und -vorverarbeitung wird einfacher sein.
Die Werkzeuge zur Erklärung von Modellen zeigen uns die Merkmale, die die Ergebnisse des Modells am meisten beeinflussen. Einige Beziehungen zwischen Merkmalen und Korrelationen mit dem Ergebnis können sehr intuitiv und Experten bekannt sein, z. B. wenn man versucht vorherzusagen, ob ein Kunde einen Kredit nicht zurückzahlen wird oder nicht, kann die Geschichte seiner Rückzahlung ein wichtiger Faktor sein. Modelle entdecken jedoch sehr oft Zusammenhänge, die der Mensch bisher nicht kannte. Dadurch können menschliche Entscheidungen in Zukunft besser ausfallen, auch wenn Sie sich nicht dafür entscheiden, sie durch das Modell zu ersetzen.
Wenn ein Modell verwendet wird, um festzustellen, ob man für etwas zugelassen wird oder nicht (ein Darlehen, eine Krankenversicherung usw.), dann muss man sicher sein, dass das Modell sinnvoll ist und eine genaue Antwort liefert. Wenn die Entscheidung auf einer undurchsichtigen Blackbox beruht, wissen Sie möglicherweise nicht, warum einer Person eine Genehmigung erteilt wurde und einer anderen nicht. Dieser Mangel an Transparenz bedeutet auch, dass es schwierig sein wird, vor Gericht zu beweisen, dass das Modell richtig funktioniert, wenn es in Zukunft Probleme mit seinen Vorhersagen gibt.
Ein interpretierbares Modell ist wichtig, um sicher zu sein, dass das Modell gut funktioniert und um Vertrauen zwischen Ihnen und Ihren Endnutzern aufzubauen. Es ist auch wichtig für das Debugging des Modells, das Ihnen helfen kann, Probleme schnell zu isolieren und zu beheben, bevor das Modell in der Produktion eingesetzt wird.
Eine Erklärung des Modells ist auch dann nützlich, wenn Sie die aktuelle Version Ihres Modells nicht verwenden wollen - indem Sie die Erstellung einfacherer Alternativen ermöglichen oder das Wissen der menschlichen Experten erweitern und ihre Entscheidungen verbessern.
Wenn Sie schließlich die Einhaltung von Vorschriften überprüfen müssen, wird eine interpretierbare Version Ihres Modells diese Verfahren erheblich erleichtern.
Ich hoffe, Sie haben diesen Artikel auf Ihrem Weg zur Datenwissenschaft als nützlich empfunden. Bitte besuchen Sie unseren Blog für weitere Artikel!
Ziel des Projekts ist die Entwicklung eines fortschrittlichen Systems, das die Erkennung von Fehlern, Störungen und andere Probleme in der elektrischen Infrastruktur und verbessert so deren Sicherheit und Effizienz.
1. Datenerfassung durch Kameras:
Er hat Hunderte von Stunden Videomaterial von Drohnen aufgenommen und sich dabei auf Stromleitungen konzentriert.
2. Datenbeschriftung:
Die Kommentatoren kennzeichneten die Daten und markierten verschiedene Bereiche, die überwacht werden sollten, z. B:
3. Einsatz von vortrainierten AI‑Algorithmen:
Es wurden vortrainierte Modelle auf der Grundlage von Deep Learning und Convolutional Neural Networks (CNN) verwendet.
4. Algorithmus-Feinabstimmung:
Die Algorithmen wurden für die Vorhersage von Störungen in der elektrischen Infrastruktur durch Training mit markierten Daten feinabgestimmt.
5. Offline-Experimente mit historischen Daten:
Erzielung einer Genauigkeit von 92% bei historischen Daten, die als Ausgangspunkt für weitere Verbesserungen dient.
6. Datenerhebung und Algorithmusvalidierung:
Es wurden zusätzliche Daten gesammelt und zur Bewertung des Algorithmus verwendet, wobei eine Genauigkeit von 89,5% erreicht wurde.
7. Iterationen zur Verbesserung des Algorithmus:
Es wurden Ensemble-Techniken angewandt, bei denen die Ergebnisse verschiedener Modelle kombiniert wurden, was zu einer Genauigkeit von 94% führte.
8. Arbeiten zur Verkleinerung von AI‑Modellen:
Um den Einsatz auf den Zielgeräten zu ermöglichen, wurde das Modell unter Beibehaltung seiner Wirksamkeit optimiert.
9. Pilot - Einsatz des Algorithmus an zwei Teststandorten:
Der Algorithmus wurde unter realen Bedingungen an zwei Standorten getestet, um eine Bewertung und Anpassung an unterschiedliche Geländebedingungen zu ermöglichen.
10. Erzeugen von Drohnenflugberichten:
Der Algorithmus wurde in Drohnen integriert, so dass nach jedem Drohnenflug Berichte mit Überwachungsergebnissen erstellt werden konnten.
Die Gesamtkosten des Projekts beliefen sich auf 800.000 PLN und verteilten sich wie folgt:


