Do you ever wonder how algorithms work that select the ads you see? Or why do you get certain posts on social media?
These tasks are handled by recommender systems. At COGITA, the company I managed, building such systems is our specialty. Our team created them for many large companies.
Today, I would like to share some of our knowledge with you, which has made us so effective in this field. I will share various tips that will help you create good systems for your company or clients.
What is a recommender system?
As a reminder, a recommender system is an algorithm that suggests tailored products, ads, content, events, etc., to users (https://en.wikipedia.org/wiki/Recommender_system). It can be placed, for example, in an online store as a “Featured Products” or “You Might Also Like” panel.
Machine learning algorithms handle this problem best. You do not need to explicitly specify user or product features for recommendation. Instead, the algorithm learns from a properly constructed training set.
Recommender system as binary classification
Let’s try to approach this problem as a supervised learning problem (unsupervised learning has much fewer possibilities and often is not sufficient).
So, for each event (e.g., purchase or click), we need to determine the target of our prediction. Do you have any idea what it might be?
The answer is simple – our algorithm for each user-product pair will predict whether the user will buy or not. More precisely – what is the probability that the user will click/buy. Then the recommendation will consist of suggesting the product(s) with the highest probability of being attractive to the user. We see that the recommendation task has been reduced to binary classification.
Notice also that we are not very interested in the exact probability value returned by the model. Only the order of probabilities for products for a particular user matters (this will be important later in the article).
Problem with the data set
In such an approach to recommendation as a classification task, however, several problems arise.
The first one is that it is difficult to build a training set. Why? As we know, for binary classification, the data set must have both positive and negative examples. However, if you gather information about historical purchases or views, you’ll only see what the user bought/viewed but not what they DID NOT buy/view. So, you will only have positive examples.
A natural solution is to assume that if user U bought only product A on a given day, then they did not buy products B, C, D, … etc. So, the training set could look like this:
Let’s assume we have 3 products P1, P2, and P3 and users U1, U2, U3, U4. Let’s assume that users U1, U2, and U3 bought one product each, and their purchases are (U1, P1), (U2, P2), and (U3, P3), then the training set is:
U1, P1, 1
U2, P2, 1
U3, P3, 1
U1, P2, 0
U1, P3, 0
U2, P1, 0
U2, P3, 0
U3, P1, 0
U3, P2, 0
U4, P1, 0
U4, P2, 0
U4, P3, 0
U4, P4, 0
where the last value 0/1 indicates whether it is a positive or negative example. So, we have simply created all other user-product pairs and put zero where there was no transaction.
However, two more problems arise here. First, can we assume that every user who did not buy a certain product had the opportunity to buy it but chose not to? Maybe there was only one piece of product P1, and when U1 bought it, U2 could not buy it anymore? Maybe it was not available at that time? It all depends on the specific situation, but you have to be very careful with this assumption because assuming a simple completion with zeros of the full Cartesian product of users x products may not be correct.
The situation gets even more complicated, for example, in the case of physical stores, each of which may be slightly differently stocked, and moreover, the stock changes every day. In this case, when creating a set, you need to select products for each customer based on inventory levels, i.e., products that (at least theoretically) the customer could have seen but did not buy.
The second problem is the potentially huge size of our matrix. If there are thousands of users and products, the matrix will have millions of rows, with the vast majority being zeros.
Negative sampling
To solve the problem of the sparse matrix, so-called negative sampling is performed. We do not want to generate all zero rows to avoid bloating the matrix but only a small subset – one that is necessary to train our model.
It turns out that if we represent our set in the following way
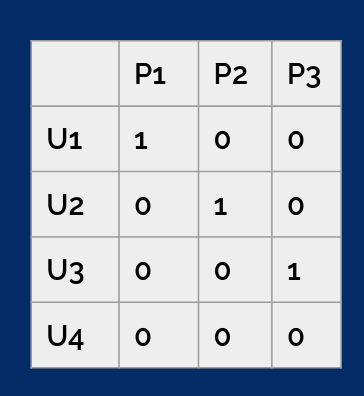
(rows are users, columns are products),
we can remove the same percentage of zeros from each column, for example.
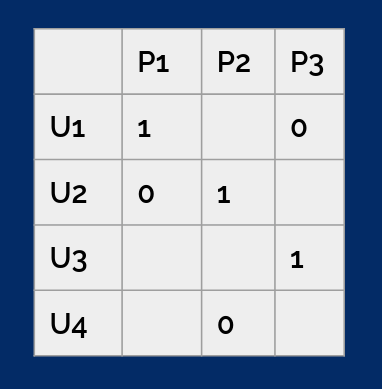
It is easy to prove mathematically that if we remove the same percentage of zeros from each column, the order of purchase probabilities will not change.
If now our algorithm is trained on this modified set, the returned probabilities will change, but the order of products for a specific user will not, which is what matters to us.
Notice one more thing. If we leave negatives (i.e., products that a given user did not buy), they should be as close as possible to actual purchases. This way, the model will have a harder task, and during training, it will gain much greater precision. So, if, for example, we want to recommend movies and we see that a given user watched only comedies, it is best if in the negatives set for that user, there are only comedies (that the user did not watch). If there were movies of another genre, the model would not learn to precisely select movies, but it would only hit the genre, always suggesting some comedy (not necessarily tailored to the user’s taste).
You can find various negative sampling algorithms, for example, in this article.
We will come back to “intelligently” choosing negatives in the next section.
Generating predictions
If we have already solved the problem with the dataset, we can create it and we have trained the model, the difficulty of calculating predictions for each user arises.
Again, we have to deal with bloating our set. If we want to return a recommendation for each user, we need probabilities for each product for each user. So, the size of the set to be calculated by the model can be many millions of rows.
The solution to this is to generate candidate sets for each user.
The idea is that the model does not have to calculate all predictions for each user. It is worth considering whether there are any other product features in our set that allow us to filter many of them and calculate predictions only for a subset of products? These can be, for example, globally popular products; products that the user viewed in the last week, or products purchased by similar users (similarity can be defined in various ways).
It is worth controlling what percentage of all positives we can cover with such candidate generation rules. The rules for creating candidate sets should allow us to capture as many real purchases as possible in the training set.
Notice now that the same candidate selection rules can be applied to selecting negatives during model training. This way, the model will not only train better (getting more realistic, and therefore more difficult examples) but also its task on the test set will be similar.
Creating additional features
Finally, I will give you one more tip that is crucial for effectively training a recommender model. It is the smart generation of new features for the model.
Notice that if we create our training set, we will have columns about the user (e.g., age, gender, interests), about products (e.g., name, price, category), as well as interactions between users and products (e.g., how many times the user bought a particular product, when was the last time, etc.).
When creating the training set, we can and should generate additional features ourselves, which are not in the set. We should not assume that the model will learn everything on its own, since we can deduce these features from other columns. From my experience, the more information we provide directly, the easier it will be for the model. Notice that XGBoost-type models are a combination of many decision trees and do not have the ability to “learn” relationships like the product of two columns (they can only approximate them heuristically with some rules).
So, it is worth adding as many new features as possible, such as:
- number of purchases per product globally,
- number of views (e.g., in an e-commerce store) of a given product by the user in the last day/week/month,
- maximum similarity metric between our user and another user who bought the given product.
Summary
In this article, I’ve presented to you the most interesting ideas we use when building recommender systems. Finally, a task for you. Choose any set to build a recommender system (e.g., from here) and try to train an XGBoost model, applying the rules I’ve listed in this article.
Let me know in the comments how it went with this task! If anything is unclear, feel free to write to me: adam.dobrakowski@cogita.ai