Jesteśmy obecnie świadkami rewolucji technologicznej, która zmienia oblicze wielu branż, przynosząc ze sobą niewyobrażalne wcześniej możliwości. Νa czele tych zmian stoi sztuczna inteligencja.
Jednak wykorzystanie jej potencjału w firmie nie jest prostym zadaniem.
Z tego wpisu dowiesz się, co zrobić krok po kroku, by wdrożyć rozwiązania oparte o AI w Twojej organizacji.
Czy AI to czat GPT?
Na początku rozprawimy się z pewnym mitem. Wiele osób myśli, że sztuczna inteligencja to tylko czat GPT lub ewentualnie inne modele do generowania tekstu czy grafiki.
W rzeczywistości AI istniało długo wcześniej niż te narzędzia. Są one tylko przykładami generatywnego AI, czyli pewnego podrodzaju sztucznej inteligencji. Polega on na generowaniu pewnych treści przez model, takich jak tekst, grafika, dźwięk, czy wideo.
Musimy jednak pamiętać, że istnieją inne rodziny modeli AI, takie jak na przykład modele predykcyjne, czy optymalizacyjne, które działają zupełnie inaczej. Ich zadaniem jest przewidywanie różnych wartości, a nie generowanie treści.
Wybranie odpowiedniego modelu powinno wynikać z potrzeb Twojej firmy i procesów, które potrzebujesz usprawnić.
Na czym polega wdrożenie AI?
Czy wystarczy w takim razie odpowiednio zidentyfikować obszar, a następnie poszukać na rynku gotowych narzędzi AI?
Niestety nie. Po pierwsze dlatego, że AI rozwija się intensywnie od niedawna, a po drugie – z powodu dużego zróżnicowania potrzeb firm – do większości zastosowań nie istnieją gotowe produkty o wysokiej jakości.
Zwykle wdrożenie AI polega na zaprojektowaniu i zaimplementowaniu szytego na miarę oprogramowania przez wykwalifikowanych specjalistów.
Jest to kilkuetapowy proces, który pozwala zarządzać ryzykiem na każdym etapie i zapewnić maksymalny zwrot z inwestycji.
1. Zrozumienie potrzeb i identyfikacja obszarów
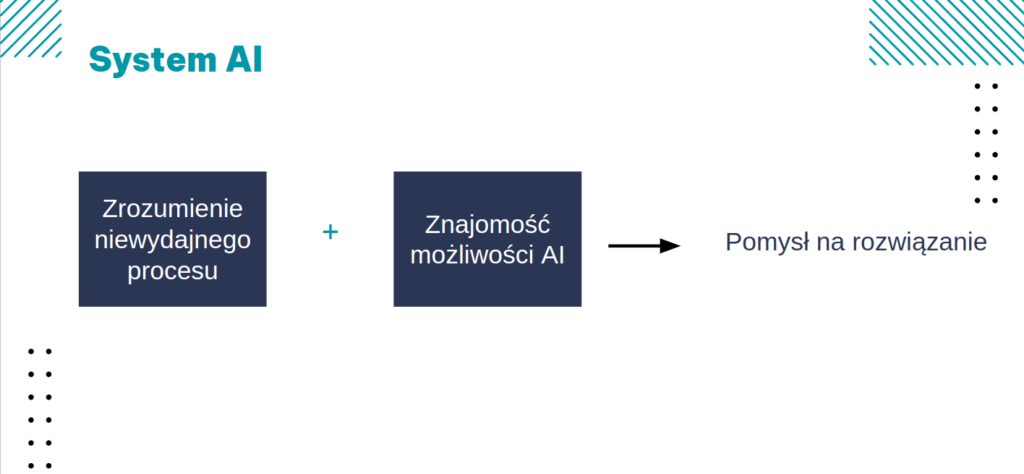
Przykłady problemów najczęściej rozwiązywanych przez AI:
A. Powtarzalna, żmudna praca człowieka
Może to być na przykład zbieranie informacji z zamówień mailowych, tworzenie podobnych dokumentów czy zadawanie klientom powtarzających się pytań.
Rozwiązaniem są tutaj systemy do analizy tekstu, czatboty czy wektorowe bazy danych i RAG-i.
B. Skomplikowane zadanie (zbyt dużo zmiennych)
Ten problem występuje przy takich aspektach, jak planowanie produkcji, zarządzanie magazynem, czy przewidywanie usterek maszyn.
Do rozwiązania wykorzystuje się systemy agentowe, cyfrowe bliźniaki, czy tzw. klasyczne uczenie maszynowe – modele uczące się na danych tabelarycznych.
C. Niewykorzystany potencjał w zgromadzonych danych
Często jest tak, że firmy gromadzą dane od wielu lat o klientach, czy produktach. Wykorzystanie wiedzy w nich zawartej, pozwala na znaczne zwiększenie sprzedaży czy ograniczenie strat, poprzez personalizację doświadczenia klienta, czy przewidywanie trendów.
Wykorzystuje się do tego algorytmy predykcyjne i optymalizacyjne trenowane na danych historycznych. Rozwiązaniem mogą być systemy rekomendujące, np. produkty, czy rabaty dla klientów.
2. Definiowanie celów i strategii
Wbrew temu, co często powtarza się w mediach w związku z szumem wokół AI, algorytmy bardzo rzadko są w stanie całkowicie zastąpić pracę człowieka. Zwykle wymagają kontroli i nie pozwalają na osiągnięcie stuprocentowej skuteczności.
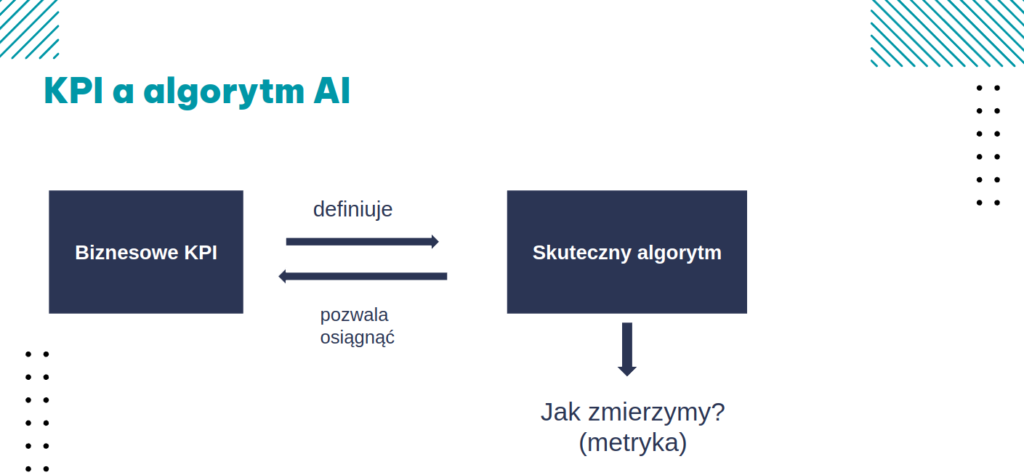
Jak wyznaczyć odpowiednią metrykę? Może to być na przykład procent poprawnych odpowiedzi, odsetek wykrytych błędów, czy średnia różnica w predykcji ceny w stosunku do wyceny wykonanej przez człowieka.
Ważne jest jednak, że metryka skuteczności nie jest jedynym ograniczeniem, bo do tego mogą dochodzić wymagania czasowe na algorytm (zwłaszcza jeśli ma działać w czasie rzeczywistym, np. na stronie internetowej), czy koszty implementacji.
3. Opracowanie prototypu / Proof-of-concept
4. Analiza danych i wybór podejścia do modelu
W zależności od ilości danych, jakimi dysponujemy oraz od oczekiwanych rezultatów, możliwe są trzy poziomy budowy modelu AI.
I) Użycie istniejącej archtektury
W tym podejściu wykorzystujemy modele wytrenowane na dużych korpusach danych, na przykład tekstowych, tzw. modele fundamentalne (foundations models). Dzielą się one na modele zamknięte (np. GPT4, Gemini), których kod nie jest udostępniony oraz modele otwartoźródłowe – open-source (np. LLaMA), których kod jest dostępny i możliwy do uruchomienia na lokalnej infrastrukturze, co zapewnia wysoki poziom ochrony danych.
Wystarczy nam wówczas próbka ok. 100 przykładów naszych danych (np. dokumentów), by sprawdzić działanie tych modeli i zobaczyć, czy spełniają nasze wymagania.
II) Dostrajanie modelu (fine-tuning)
Jeśli mamy od kilkuset do kilku tysięcy przykładów treningowych, możemy nie tylko wykorzystać model fundamentalny, ale dostosować jego działanie tak, aby lepiej odpowiadał na naszą potrzebę biznesową.
Przykładowo, możemy dostosować styl generowanych tekstów do standardów naszej firmy, czy też zaimplementować wykrywanie na obrazach elementów kluczowych dla naszych procesów biznesowych (np. wykrywanie usterek w produkowanych częściach czy rozpoznawanie produktów).
III) Pełny trening modelu AI
Jeśli mamy większą ilość danych, zwykle co najmniej kilkadziesiąt tysięcy, możemy wytrenować własny model od podstaw. To podejście często pozwala na uzyskanie najwyższej skuteczności, bo wykorzystuje precyzyjnie tylko te dane, które powstają w konkretnym przedsiębiorstwie.
5. Implementacja i wprowadzenie na rynek
Na tym etapie model jest trenowany i testowany na danych historycznych. Jeśli spełnia zakładane wartości metryk, powinna nastąpić decyzja o wdrożeniu go dla użytkowników końcowych.
Częstym wyzwaniem na tym etapie jest tzw. interpretowalność czy też wyjaśnialność modelu. Jest to cecha, która świadczy o tym, czy rozumiemy, dlaczego model zwrócił taki wynik, czy nie. Jest to często ważny aspekt z punktu widzenia biznesowego lub prawnego, zwłaszcza gdy predykcje modelu są błędne lub kontrowersyjne.
Niektóre modele mają taką cechę, inne nie. Istnieje też wiele podejść, które pozwalają na przybliżanie tej cechy za pomocą innych modeli.

Teraz też jest ostatni moment na podjęcie decyzji, czy model będzie działał np. w chmurze, czy też lokalnie, oraz jak się będzie komunikował z istniejącą infrastruktują IT. Model zostaje teraz opakowany w wygodny interfejs użytkownika.
Na tym etapie dokonuje się również ostatecznej weryfikacji poprawności modelu. Pamiętajmy, że nawet najlepsze modele, działające na danych historycznych, mogą z różnych powodów nie działać tak dobrze w rzeczywistym środowisku.
6. Monitorowanie, optymalizacja i skalowanie
Teraz możemy być naprawdę dumni z siebie i z naszego zespołu! Mamy działający model, osiągający zakładane KPI i generujący zyski.
Aby jednak uniknąć bolesnego rozczarowania po pewnym czasie, potrzebujemy wykonać jeszcze pewne kroki.
Pierwszym z nich jest odpowiednie monitorowanie działania modelu. Potrzebujemy tutaj nie tylko mierzyć parametry systemowe (czy model działa, jak szybko zwraca predykcje itp.), ale również jego skuteczność czy też parametry danych wejściowych. Częstym problemem jest przykładowo wprowadzenie nowych produktów przez firmę, na których model wcześniej nie był trenowany i z którymi sobie nie radzi.
Pamiętajmy też, by użytkownicy mieli możliwość feedbacku. Kciuki w górę/w dół widoczne w ChatGPT? OpenAI gromadzi oceny od użytkowników, które umożliwiają trenowanie kolejnych generacji modeli. Innym pomysłem mogą być regularne ankiety dla użytkowników.
Ostatni etap to również powrót do pierwszego kroku – analiza procesów firmy po wdrożeniu algorytmu i dalsze decyzje – może model można zastosować również w innych działach lub jednostkach firmy?
Dalsze kroki
Mamy nadzieję, że ten poradnik będzie przydatny w Twoich projektach AI. Dodatkowo przygotowaliśmy dokument – checklistę – który zawiera cały ten proces rozpisany punkt po punkcie, abyś nie zapomniał o żadnym kluczowym kroku wdrażając systemy AI.